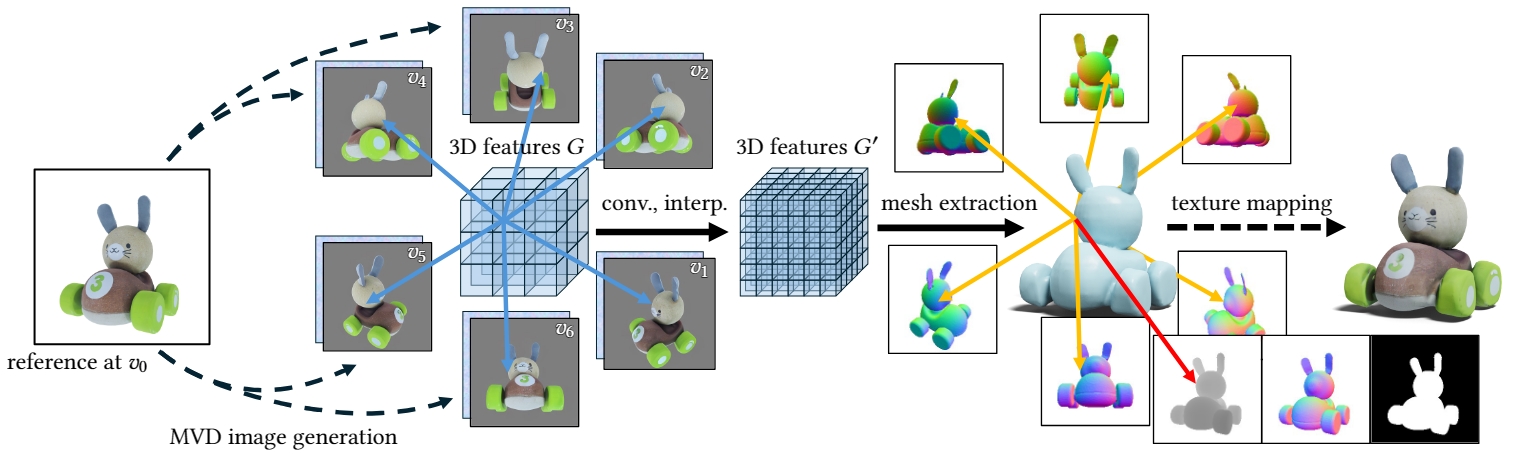
Multiview diffusion (MVD) has emerged as a prominent 3D generation technique, acclaimed for its generalizability, quality, and efficiency. MVD models finetune image diffusion models with 3D data to generate multiple views of a 3D object from an image or text prompt, followed by a multiview 3D reconstruction process. However, the sparsity of views and inconsistent details in the generated multiview images pose challenges for 3D reconstruction. We present MVD2, an efficient 3D reconstruction method tailored for MVD images. MVD2 integrates multiview image features into a 3D feature volume, then transforms this volume into a textureless 3D mesh, onto which the MVD images are mapped as textures. It employs a simple-yet-efficient view-dependent training scheme to mitigate discrepancies between MVD images and ground-truth views of 3D shapes, effectively improving 3D generation quality and robustness. MVD2 is trained with 3D collections and MVD images, and the trained MVD2 efficiently reconstructs 3D meshes from multiview images within one second and exhibits great model generalizability in dealing with images generated by various MVD methods.